TEFCluster
Investigating further text analysis of TEF2 statements
Exploring the Teaching Excellence Framework (TEF) 2017 submissions using topic modelling to look for language differences between awards. Work for PGCert assignment 2019-20. (All the code is available on GitHub, it will be available CC-BY licenced for the community to adapt and use.)
Contents
Live interactive visualisations
- See the 🇬🇧whole visualisation
- See breakdown by award: 🥇gold visualisation, 🥈silver visualisation and 🥉bronze visualisation
- See breakdown by level: 🏨HEI visualisation and 🏫FEC visualisation
1. Introduction
The Teaching Excellence Framework (TEF) is a major policy initiative in higher education. Moore, Higham, Sanders et al. (2017) explain how the submissions made by providers in the TEF Year Two (TEF2) process provided a detailed source of evidence for excellence in teaching and impact evaluation practice. The Higher Education Academy (HEA) commissioned a research team to devise and undertake a data mining process on the text content of each submission. The results provided an initial guidance of a gold, silver or bronze award, some of which were adjusted by a panel before deciding a final outcome (Kernohan (2017)).
There are further data mining techniques and visualisation tools which can be used to study the submission texts in the following ways:
- To look at what UK education institutions are saying as a whole.
- To compare statements of institutions by the award they were given.
- To compare statements of higher and further education levels.
These findings may be able to assist or guide future work. The R programming language has been used to prepare and analyse the data files.
2. Method
The TEF2 statement texts and award data were downloaded from the Office for Students website. These data files are available in CSV and/or Excel format. The statements are available in PDF format. Work was required to convert and interpret files using R.
LDA (Latent Direchlet Allocation) is a topic modelling technique that has been used to analyse the statements. It has been applied in previous work by Poon, Goloshchapova et al. (2018). The statements (documents) are taken through a series of pre-processing steps including stemming and removing stop-words, then the LDA process (‘text2vec’) is applied. The pre-processing could be further improved after running the LDA process the first time by customising the list of stop-words or by tokenising instead of stemming.
The LDA process aims to identify topics that are covered in one or more documents by looking at the frequency and co-occurence of words. A hyper-parameter for this model, ‘number of latent topics’, was set to 50.
Two output matrices are produced:
- A list of 50 keywords for each of the topics selected.
- The probability of relevance of each topic in each document.
The six most likely keywords are shown in the analyses below. These lists are useful for identifying garbage terms, some of which could be removed if re-running the process. The identified topics may include terms which a human can identify as being related to the same real topic.
The ‘LDAvis’ software is used to visualise the topics, list which terms have been identified, and map how the topics relate to each other. (Topics with more terms in common appear in close proximity on the intertopic distance maps). Interpreting the LDAvis output can help to further refine the LDA process.
After running the LDA process on the whole set of documents, it was repeated with subsets for each of the gold, silver and bronze awarded institutions, with a visualisation for each. It was also repeated with subsets for higher and further education institutions.
3. Analysis
Most salient terms
These terms are most important within the identified topics. Note that all terms have been stemmed (the ends of words are removed so that ‘support’, ‘supporting’ and ‘supported’ are treated the same, for example).
| Rank | 🇬🇧Whole | 🥇Gold | 🥈Silver | 🥉Bronze | 🏨HEI | 🏫 FEC |
|---|---|---|---|---|---|---|
| 1 | student | student | student | student | univers | colleg |
| 2 | univers | univers | univers | colleg | student | student |
| 3 | colleg | teach | colleg | univers | teach | learn |
| 4 | learn | colleg | learn | teach | learn | educ |
| 5 | support | learn | teach | progamm | employ | support |
| 6 | teach | support | support | support | support | higher |
Most frequent terms
These terms are most frequent, regardless of topics.
| Rank | 🇬🇧Whole | 🥇Gold | 🥈Silver | 🥉Bronze | 🏨HEI | 🏫FEC |
|---|---|---|---|---|---|---|
| 1 | student | student | student | student | student | student |
| 2 | univers | univers | learn | learn | univers | colleg |
| 3 | learn | support | univers | colleg | learn | support |
| 4 | support | teach | develop | support | support | learn |
| 5 | teach | learn | teach | develop | teach | develop |
| 6 | colleg | provid | employ | univers | develop | staff |
- All institutions talk about students more than anything else.
- HEI institutions talk about universities, while LEC institutions talk about colleges, as one might expect (although this could be when they mention their own name)
- HEI institutions talk more about employment/employability and teaching than FEC.
- All institutions talk about teaching and/or learning a lot.
- Gold and bronze institutions talk a lot about support.
- In a brief comparison with the study of corporate social responsibility in Poon et al. (2018), the topics identified in TEF2 overlap more; the same terms appear more often in multiple topics. This could mean that TEF2 submissions use a lot of the same language as each other. Further refinement of the LDA process is required to make that claim with confidence.
Major topics
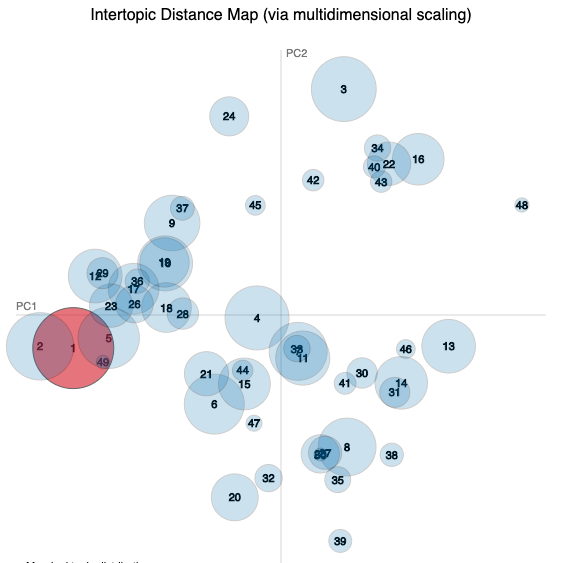
These are the six most salient terms from each of the five widest distributed topics for each study (the largest circles in the visualisation).
- The tables are excerpts from the
*_word_vectors_for_each_topic.csvfiles. - The charts are intertopic distance maps where each circle is a topic and topic 1 is coloured red. Topics with similar terms appear close on the chart.
- See the visualisations for each study for interactive maps and tables with percentages.
🇬🇧Whole
See the 🇬🇧whole visualisation
| Topic 1 | Topic 2 | Topic 3 | Topic 4 | Topic 5 |
|---|---|---|---|---|
| support | teach | work | learn | univers |
| student | learn | research | employ | student |
| learn | student | graduat | support | teach |
| develop | success | learn | teach | undergradu |
| includ | experi | employ | skill | studi |
| feedback | demonstr | practic | profession | academ |
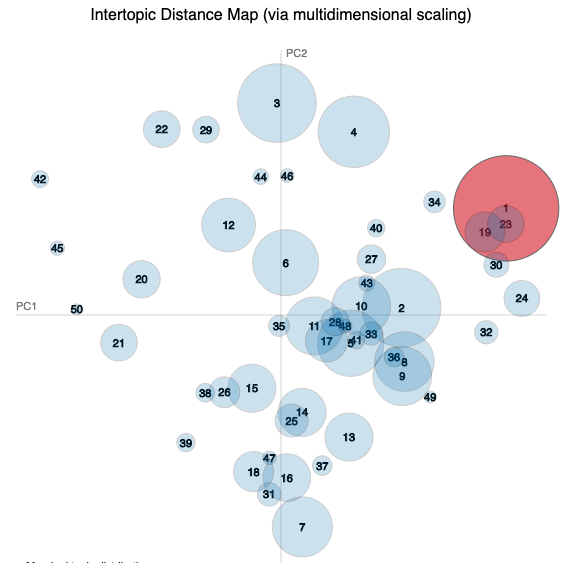
- Much overlap between topics.
- Would need to look further at all 50 topics to find ones that are clearer.
🥇Gold
See the 🥇gold visualisation
| Topic 1 | Topic 2 | Topic 3 | Topic 4 | Topic 5 |
|---|---|---|---|---|
| student | univers | student | practic | well |
| support | teach | academ | staff | first |
| improv | student | support | learn | year |
| research | learn | also | feedback | provid |
| inform | studi | use | includ | three |
| data | subject | person | programm | take |
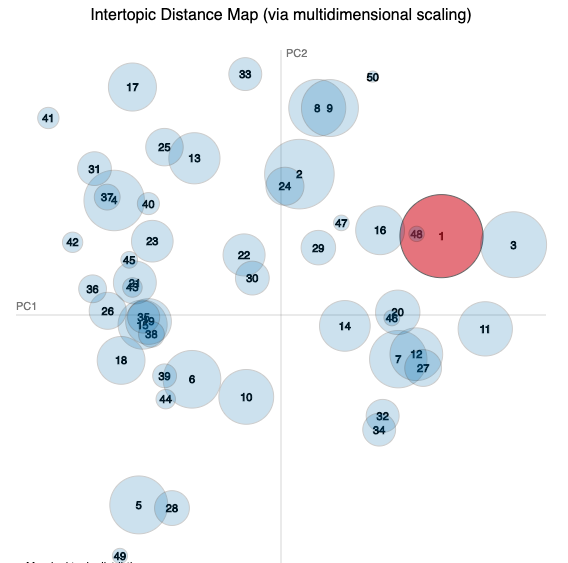
🥈Silver
See the 🥈silver visualisation
| Topic 1 | Topic 2 | Topic 3 | Topic 4 | Topic 5 |
|---|---|---|---|---|
| develop | learn | student | student | colleg |
| learn | develop | provid | metric | student |
| teach | programm | programm | tef | part |
| profession | student | feedback | employ | progress |
| staff | support | learn | data | work |
| practic | staff | access | assess | area |
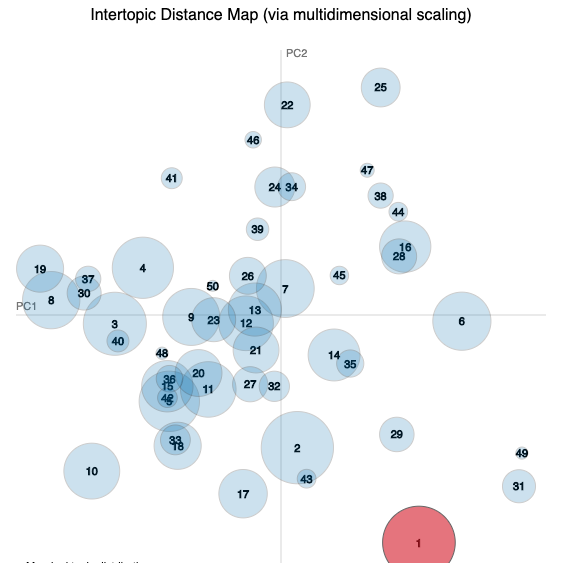
🥉Bronze
See the 🥉bronze visualisation
| Topic 1 | Topic 2 | Topic 3 | Topic 4 | Topic 5 |
|---|---|---|---|---|
| employ | student | student | colleg | learn |
| work | learn | staff | higher | ukprn |
| skill | develop | develop | provis | can |
| feedback | project | support | develop | name |
| use | support | higher | learn | event |
| student | research | innov | degree | offer |
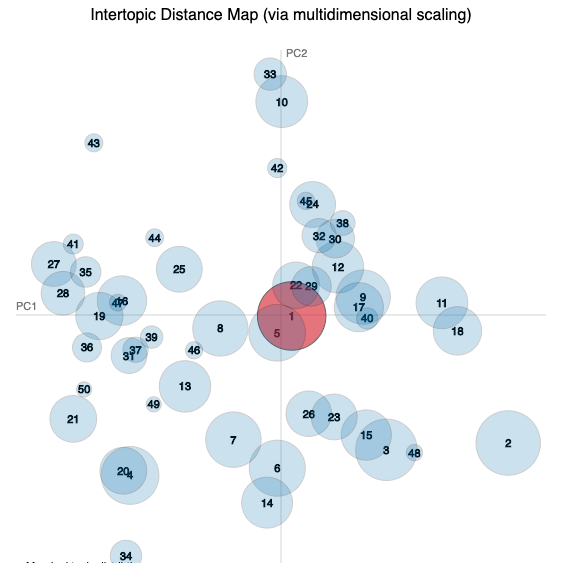
- No particular differences between gold, silver and bronze awarded institutions.
🏨HEI
See the 🏨HEI visualisation
| Topic 1 | Topic 2 | Topic 3 | Topic 4 | Topic 5 |
|---|---|---|---|---|
| student | learn | univers | develop | support |
| feedback | develop | student | learn | employ |
| academ | work | employ | research | teach |
| offer | experi | studi | staff | sector |
| work | profession | enhanc | institut | improv |
| librari | staff | engag | provid | work |
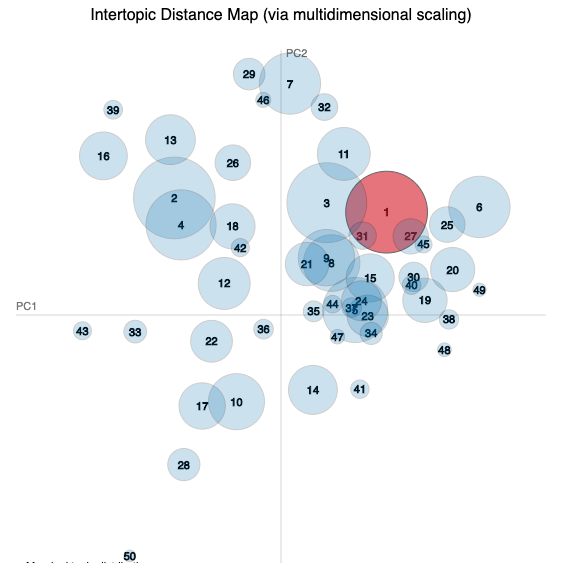
🏫FEC
See the 🏫FEC visualisation
| Topic 1 | Topic 2 | Topic 3 | Topic 4 | Topic 5 |
|---|---|---|---|---|
| student | student | colleg | employ | student |
| support | develop | educ | higher | within |
| skill | learn | learn | progress | engag |
| use | support | work | programm | academ |
| cours | skill | provis | student | develop |
| develop | work | curriculum | ensur | support |
4. Conclusions
- LDA analysis can help to further understand the results as a whole.
- We can be reassured that the process confirms the most obvious expectations (the main focus is students, teaching and learning).
- We can begin to identify topics but there is much overlap.
- So far, there are no outstanding differences between gold, silver and bronze awarded institutions.
- More work is required to refine the process; it might work better if the data set was larger or if the pre-processing was customised further. The code could be further optimised.
- We could extend to look at multiple years of submissions.
5. References
Moore, J, Higham, L, Sanders, J, Jones, S, Candarli, D, Mountford-Zimdars, A 2017, ‘Evidencing teaching excellence: Analysis of the TEF2 provider submissions’, Higher Education Academy.
Office for Students 2019, TEF data, Office for Students.
Poon, S-H, Goloshchapova, I, Pritchard, M & Reed, P 2018, ‘Corporate Social Responsibility Reports: Topic Analysis and Big Data Approach’, European Journal of Finance.
Kernohan, D 2017, ‘TEF results - Who moved up and who fell down?’, Wonkhe.
6. Directory structure
data/
raw/(excluded from version control)tef_y2_allcontext.csvcontextual datatef_y2_allmetrics.csvall the metricstefyeartwo_awards.xlsxall the outcomes/awardsTEFYearTwo_AllSubmissions/folder- 232 files with names such as:
10000055_Abingdon and Witney College_Submission.pdfPROVIDER_TEFUKPRNunderscorePROVIDER_NAMEunderscore.pdf
TEFYearTwo_AllSubmissions_txt/folder- We convert all the PDF documents to TXT files.
processed/tdm.rdstext document matrix data for the whole (may use later)gold_tdm.rdstext document matrix data for the gold awardssilver_tdm.rdstext document matrix data for the silverbronze_tdm.rdstext document matrix data for the bronzehei_tdm.rdstext document matrix data for higher educationfec_tdm.rdstext document matrix data for further education
code/
convert_pdf2txt.RConvert directory in one go from PDF to txttext2vec_whole.RPerform LDA (column for award) and create visualizationtext2vec_gold.RJust gold awarded institutions (run after ‘whole’)text2vec_silver.RJust silver awarded institutions (run after ‘whole’)text2vec_bronze.RJust bronze awarded institutions (run after ‘whole’)text2vec_hei.RJust ‘HigherEducationInstitution’ (run after ‘whole’)text2vec_fec.RJust ‘FurtherEducationCollege’ (run after ‘whole’)
result/
LDA_plot.RmdThe knitR file to launch the visualizationLDA_plot.htmlThe knitted visualizationwhole_doc_topic_probabilities.csvProbability of each topic in each docwhole_word_vectors_for_each_topic.csvWhich words occur in which topicsldavis/folder- The HTML, CSS and JavaScript files for the
LDA_plot.htmlfile
- The HTML, CSS and JavaScript files for the
LDA_plot_gold.RmdLDA_plot_gold.htmlgold_doc_topic_probabilities.csvgold_word_vectors_for_each_topic.csvgold_ldavis/folderLDA_plot_silver.RmdLDA_plot_silver.htmlsilver_doc_topic_probabilities.csvsilver_word_vectors_for_each_topic.csvsilver_ldavis/folderLDA_plot_bronze.RmdLDA_plot_bronze.htmlbronze_doc_topic_probabilities.csvbronze_word_vectors_for_each_topic.csvbronze_ldavis/folderLDA_plot_hei.RmdLDA_plot_hei.htmlhei_doc_topic_probabilities.csvhei_word_vectors_for_each_topic.csvhei_ldavis/folderLDA_plot_fec.RmdLDA_plot_rec.htmlfec_doc_topic_probabilities.csvfec_word_vectors_for_each_topic.csvfec_ldavis/foldermaps/foldermap1_whole.pngIntertopic distance map for wholemap2_gold.pngIntertopic distance map for goldmap3_silver.pngIntertopic distance map for silvermap4_bronze.pngIntertopic distance map for bronzemap5_hei.pngIntertopic distance map for HEImap6_fec.pngIntertopic distance map for FEC